 Une équipe de chercheurs du Laboratoire des sciences de l'éducation de l'Université Grenoble-2 et du département d’informatique de l'Ecole polytechnique de Bucarest teste les premières bases d’un « tuteur informatique » capable d’identifier les stratégies de lecture mises en œuvre par des élèves afin de les aider dans leur apprentissage de la lecture.
Une équipe de chercheurs du Laboratoire des sciences de l'éducation de l'Université Grenoble-2 et du département d’informatique de l'Ecole polytechnique de Bucarest teste les premières bases d’un « tuteur informatique » capable d’identifier les stratégies de lecture mises en œuvre par des élèves afin de les aider dans leur apprentissage de la lecture.
Tout lecteur met en œuvre diverses stratégies pour évaluer en temps réel sa compréhension d’un texte lu, mais aussi pour remédier à d'éventuelles difficultés détectées comme, par exemple, identifier un personnage du texte ou comprendre les implications d'un événement.
L’usage de ces stratégies est fondamental dans l’apprentissage de la lecture et pour le bon déroulement de la scolarité d’un élève. Néanmoins, de nombreuses questions de recherche se posent concernant ces stratégies : Quelles sont-elles ? Comment se développent-elles ? Peut-on aider les élèves à acquérir les stratégies les plus favorables à la compréhension ? L'identification de ces stratégies par l'enseignant est très coûteuse en temps, et nécessite une grande expertise des mécanismes engagés dans la lecture. Un système automatisé de type « tuteur informatique » serait-il capable de réaliser cette analyse et d’identifier les stratégies utilisées par un lecteur à partir d’une verbalisation écrite de ce qui a été compris ?
C’est l’objectif que s’est donné une équipe de chercheurs du Laboratoire des sciences de l'éducation de l'Université Grenoble-2 et du département d’informatique de l'Ecole polytechnique de Bucarest (Roumanie). Inspirée par l’outil iStart développé en langue anglaise par une équipe de chercheurs de l’Institute for Intelligent Systems de l’University of Memphis (EU), l’équipe franco-roumaine a réalisé une étude sur la faisabilité d'un tel tuteur en français pour des élèves de primaire et de collège.
En centrant leur test sur la paraphrase, qui est la stratégie la plus rencontrée chez des élèves d'école primaire (redire, avec des mots pouvant être différents, l'essentiel du contenu lu), ces chercheurs ont fait lire un texte narratif (1) à 44 élèves de CE2 et CM2. Ils leur ont demandé, à 6 points prédéterminés du texte, d'arrêter leur lecture pour expliquer ce qu'ils avaient compris du passage venant d'être lu (voir figure). Ces verbalisations ont été enregistrées et transcrites, puis analysées par une méthode statistique appelée « Analyse sémantique latente » (2). Cette méthode permet de mesurer la similarité sémantique entre chaque verbalisation et le passage précédent, donc de rendre compte de la manière dont les élèves ont paraphrasé ce dernier. De plus, les verbalisations ont été analysées par deux experts, afin de déterminer quelles stratégies les élèves utilisent.
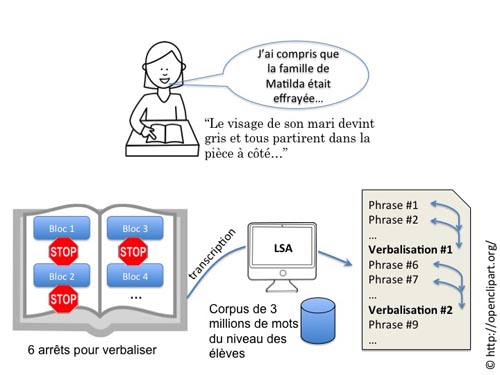
Les résultats de ce premier test montrent d’une part que les élèves ne s’appuient pas sur la récence des informations (faculté de se rappeler des derniers éléments lus) mais sur la structure narrative : les phrases causales sont en effet bien mieux rappelées que le reste du texte et cette tendance augmente avec l’âge des enfants. D’autre part, que le nombre de paraphrases détectées par les experts corrèle de manière satisfaisante avec les estimations de l’Analyse sémantique automatique (LSA), ce qui permet de considérer les résultats obtenus avec la méthode automatique comme fiables. Cette dernière permet d’analyser de manière valide les paraphrases et ouvre donc d’intéressantes perspectives dans l’élaboration d’un tuteur d’aide à l’acquisition des stratégies de lecture.
A terme, un tel tuteur, utilisé avec un logiciel de reconnaissance automatique de la parole, pourrait être utilisé pour entraîner les très jeunes élèves à réfléchir à leurs stratégies de lecture, mais aussi les amener à diversifier leurs stratégies pour améliorer leur capacité à comprendre les textes qu'ils lisent.
Les résultats de cette recherche ont fait l'objet d'une communication à la conférence européenne EARLI SIG 2 organisée par le Laboratoire des Sciences de l’Education de l’Université Grenoble-2, qui s’est tenue à Grenoble du 28 au 31 août 2012.
Notes :
(1) Extrait de Matilda, de Roald Dahl
(2) L’analyse sémantique latente (LSA, de l'anglais : Latent semantic analysis) est un procédé de traitement des langues naturelles, qui permet d'établir des relations sémantiques entre les termes d’un document ou de plusieurs documents, en construisant des « concepts » liés aux documents et aux termes. (http://lsa.colorado.edu/)
Contact chercheur :
Cette adresse e-mail est protégée contre les robots spammeurs. Vous devez activer le JavaScript pour la visualiser., laboratoire des sciences de l'éducation
Cette adresse e-mail est protégée contre les robots spammeurs. Vous devez activer le JavaScript pour la visualiser., laboratoire des sciences de l'éducation
Cette recherche est développée dans le cadre du projet DEVCOMP (responsable Maryse Bianco, UPMF) et financée par l'Agence nationale de la recherche (ANR).

